EDIT: thanks to Alvaro Videla that pointed out that a queue can be connected to more than one exchange; sorry for the wrong information.
Everyone who started using AMQP learned from the very beginning that there are three different types of exchanges, namely direct, fanout and topic. In this post, I am going to highlight some interesting properties of direct exchanges, which were not clear to me when I started using RabbitMQ.
Now some time has passed since I started, and reading the RabbitMQ tutorials again I can see that these properties are no mystery. However, in this short post I want to clearly point out three different uses of direct exchanges, in the hope that other novices will be helped to better understand those powerful components of an AMQP system.
Movie cast
The cast of an AMQP message delivery is made of three different type of components: the exchange, the queues, and the consumers.
The exchange is the container of all the messages other components sent; each message has been tagged with a routing key and they can be extracted from the exchange by means of those keys.
The consumers are those which are interested in getting messages from the exchange, so their main activity is to connect to the exchange, pick messages from it and act according to its content. A consumer can connect to more than one exchange and receive messages concurrently.
The queues are the real core of the system. They actually extract messages from the exchange according to their configuration, and you are not wrong if you think that they are the real routing component of AMQP; indeed exchanges do not exist as separate components, so the routing game is played by the channel and the queues.
Let us consider queues at a deeper level. They are two sided components, messages enter from one side and exit from the other one. Thus each queue can establish connections on both sides: on the input side a queue fetches messages from one or more exchanges while on the output side the queue can be connected to one or more consumers. From the single queue point of view being connected to more than one exchange with the same routing key is transparent, since the only thing that concerns the queue itself are the incoming messages; being connected to more than one exchange with different routing keys leads to complex scenarios, so in this article I will consider a single direct exchange delivering messages to queues.
Three configurations
As you can easily see, the most general case with direct exchanges is that of multiple queues connected to the same exchange, with multiple consumers connected to each queue.
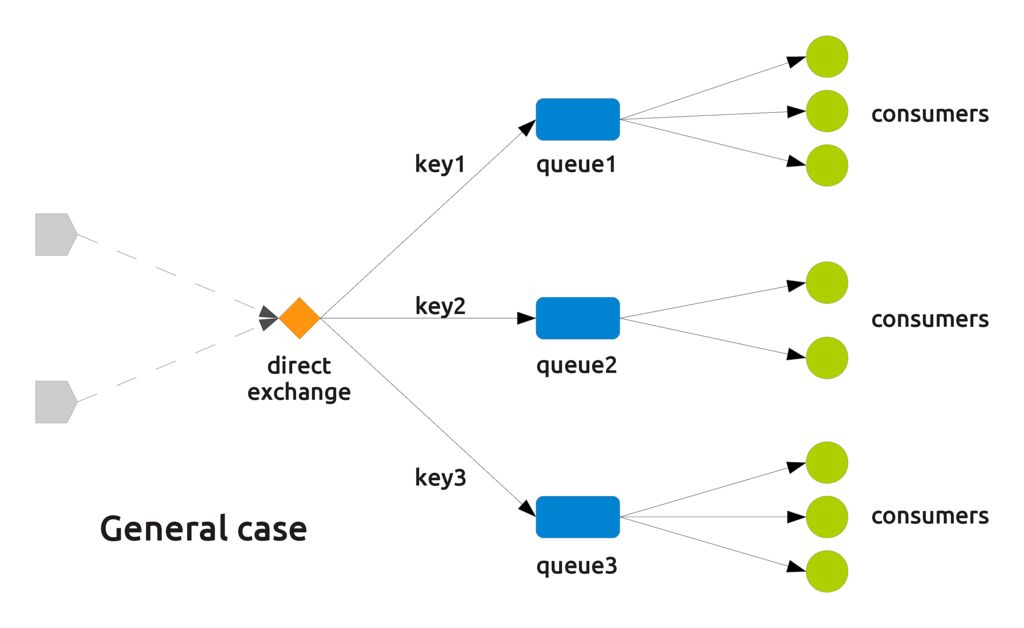
The edge cases of this configuration can be obtained decreasing the number of queues, the number of consumers, or both, to a single unit. This leads to three different configurations:
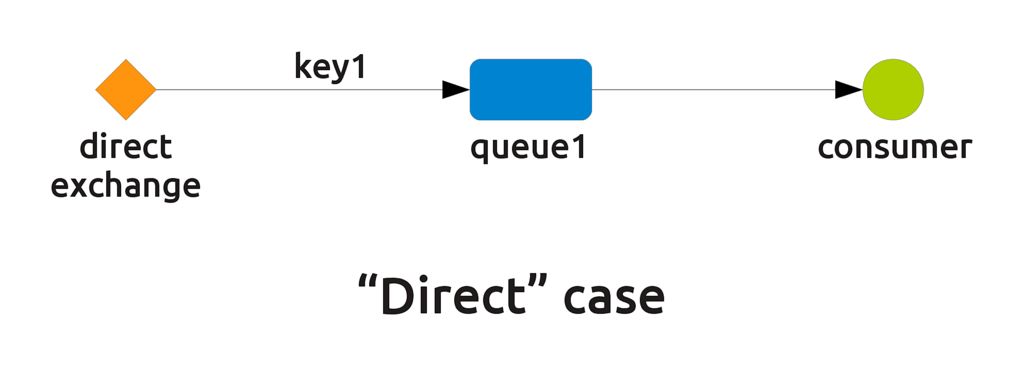
- The "direct" case (see tutorial number 1). Here, only a queue is configured with a given routing key and only a consumer is connected to that queue. Every message sent to the exchange with that routing key will be delivered to the consumer.
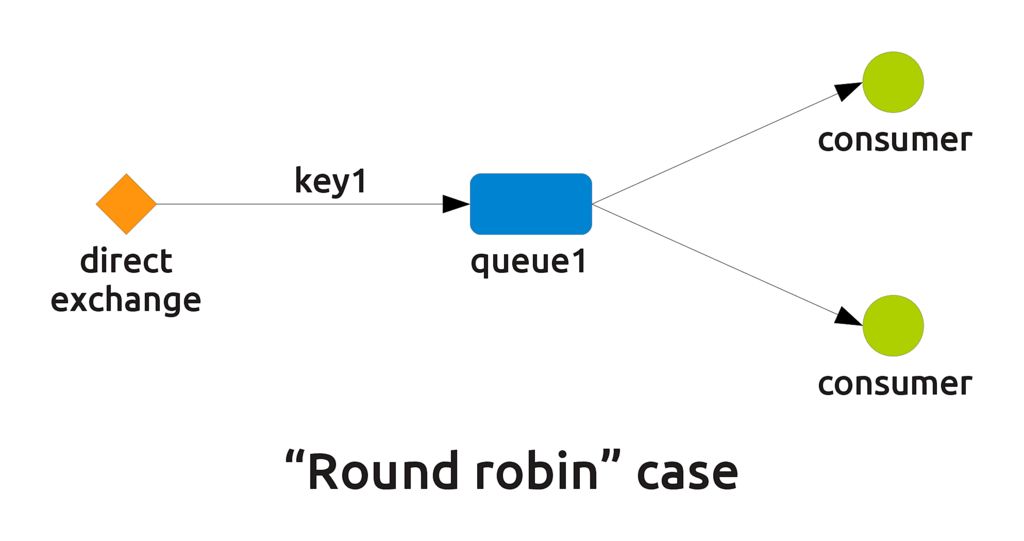
- The "round robin" case (see tutorial number 2). Here, two or more consumers are connected to the same queue (pay attention, not two queues configured with the same key), and the messages in the queue are dispatched in a round robin way, i.e. each consumer receives one of the messages until there are no more consumers, then the procedure starts again.
- The "fanout" case (see "Multiple bindings" in tutorial number 4). Here, two or more different queues configured with the same key connect to the same exchange, and each of them dispatches messages to only one consumer. Since the queues pick messages with the same routing key, messages are duplicated and dispatched simultaneously to each of them. This makes the direct exchange behave like a fanout one, but only for the queues bound with that routing key.
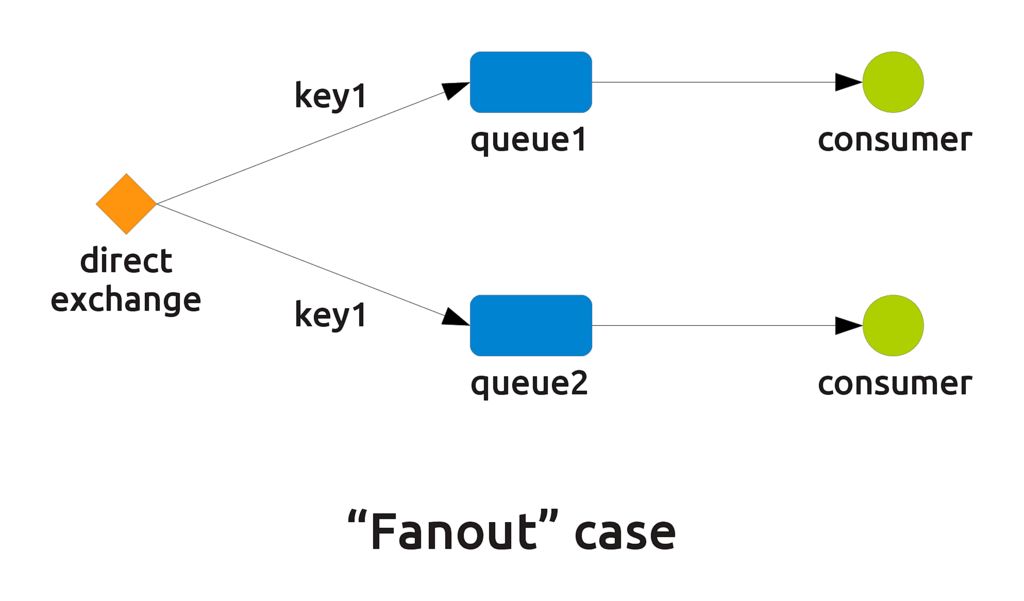
The last consideration about the fanout case is important. A pure fanout exchange is somehow limited since it can only blindly dispatch messages to everyone connects. A direct exchange can behave like a fanout only for certain keys while acting as a direct or round robin dispatcher with other keys, at the same time.
A real use case
Let us look at a concrete example to better understand why direct exchanges can be used to solve the most part of routing issues we face. Remember that in AMQP queues are named objects and that names are primary keys, i.e. there cannot be two queues with the same name under the same virtual host.
This example is a simplified version of a real RabbitMQ system running Python programs based on Postage.
In a cluster, a single program can be uniquely identified by the compound value (pid,host), since given a host only one program can have the given PID. To simplify the notation say that any program in the cluster is identified by a string of the form pid@host (for example 8669@yoda, which is the editor I'm using in this very moment). To further simplify the management of our cluster say that each program has a name, such as the name of its executable file.
Given this configuration an obvious requirement is to be able to reach programs with messages grouping them according to some of the listed properties; the possible targets of our messages are:
- All programs on a given host. This is useful for example when you are going to reset that machine, and you need to previously signal each program running on it.
- All programs running with a given name. This can be leveraged, for example, because you updated the executable or some plugins and you want them to refresh the code.
- A single program, given its unique key
pid@host. This comes in handy when you have to address a specific process, for example to gracefuly terminate it or to collect output.
All these requirements can be fulfilled by a single direct exchange and multiple queues with suitable routing keys.
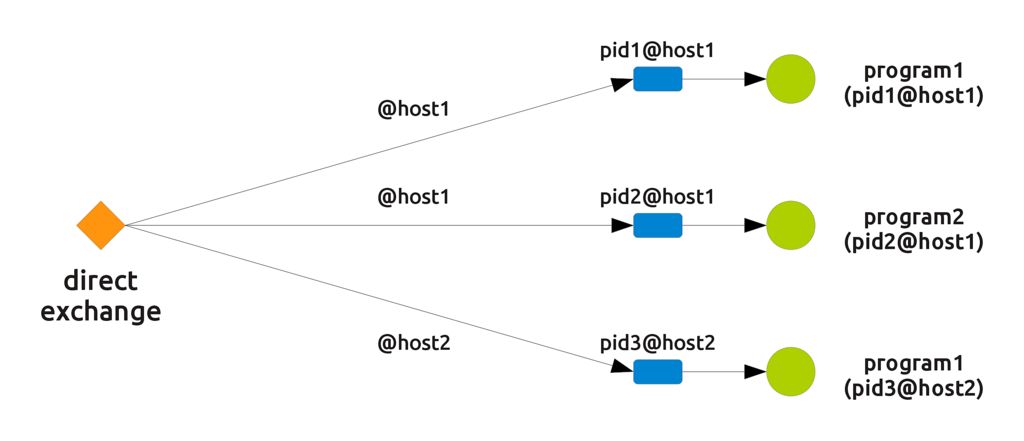
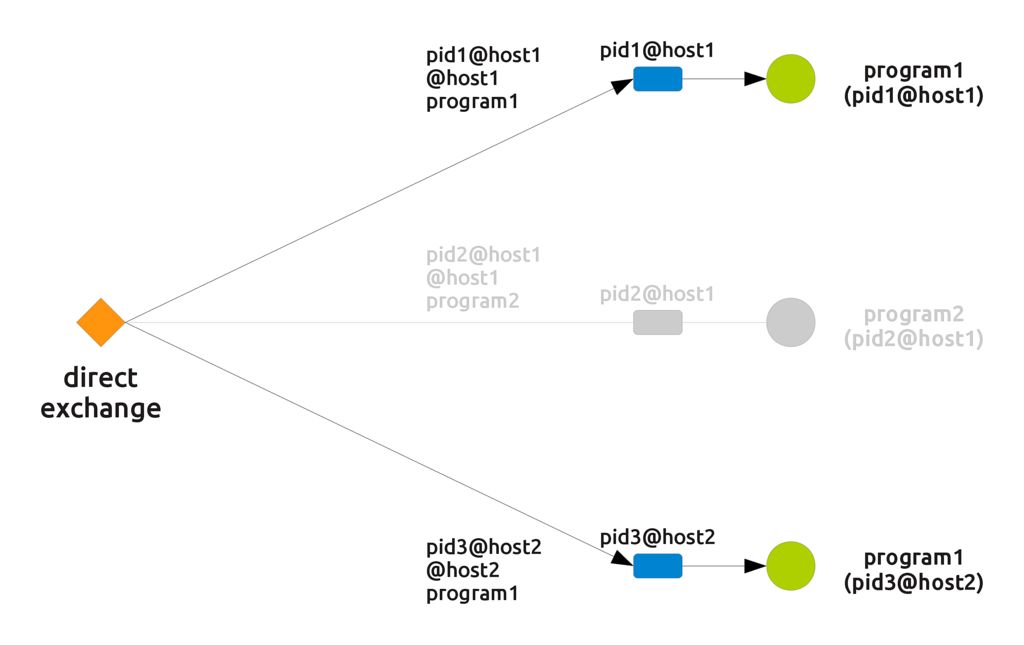
Take as an instance the first requirement: reaching all programs on a single host. You only need each program to declare a queue which is unique and to bind it to the exchange with the routing key @host, where host is the actual name of the host (@yoda in the previous example). Declaring a unique queue is simple, in that you can use the unique process name pid@host. The following picture shows the resulting setup: as you can see each queue has a unique name (its owner's unique key) and is bound to the exchange with a routing key that depends on the host.
Now some little magic. The second requirement can be fulfilled by connecting the same queue to the same exchange but with a different routing key, this time made by the program's name. The resulting setup is represented in the following picture.
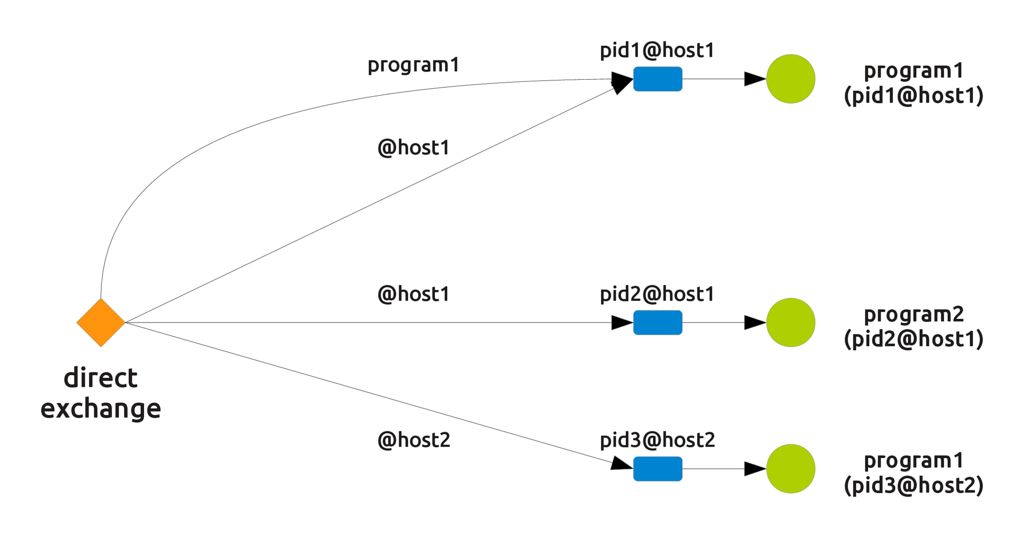
The third requirement makes us connect the same queue with the same exchange with a routing key which is the unique name of the queue.
I hear you scream "Why do you call this magic?"
Indeed it is something very simple and straightforward, but take a look at the complete setup, where, for simplicity's sake, the three connections between a queue and the exchange have been collapsed to one line.
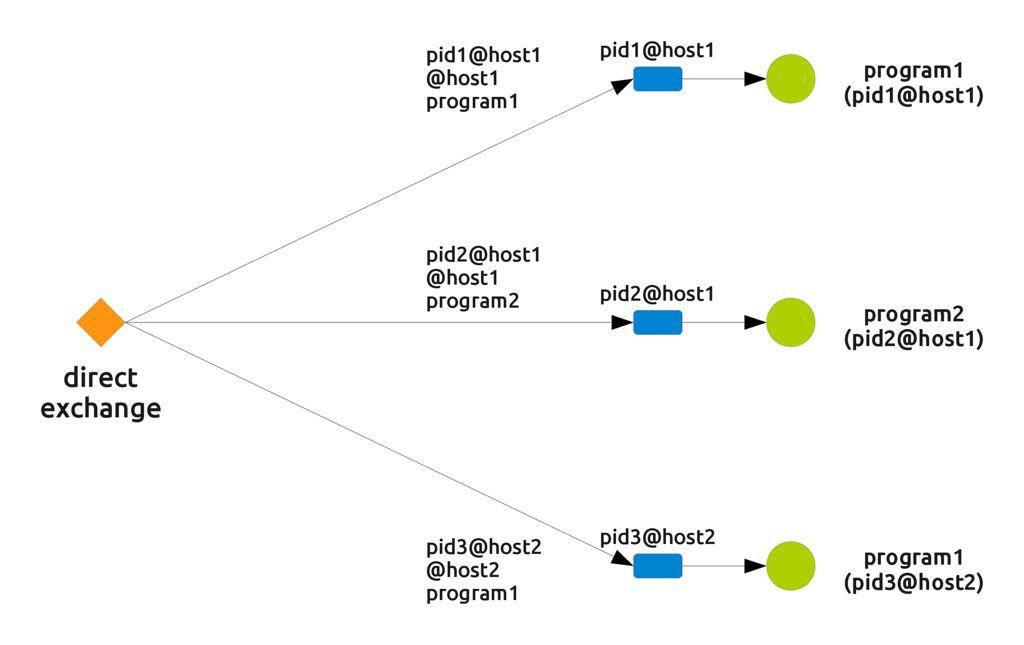
Here, we have a "selective fanout" behaviour, in that the actual "active" connections change depending on the routing key. If an incoming message is routed with the key "@host1", for example, we obtain the following connections
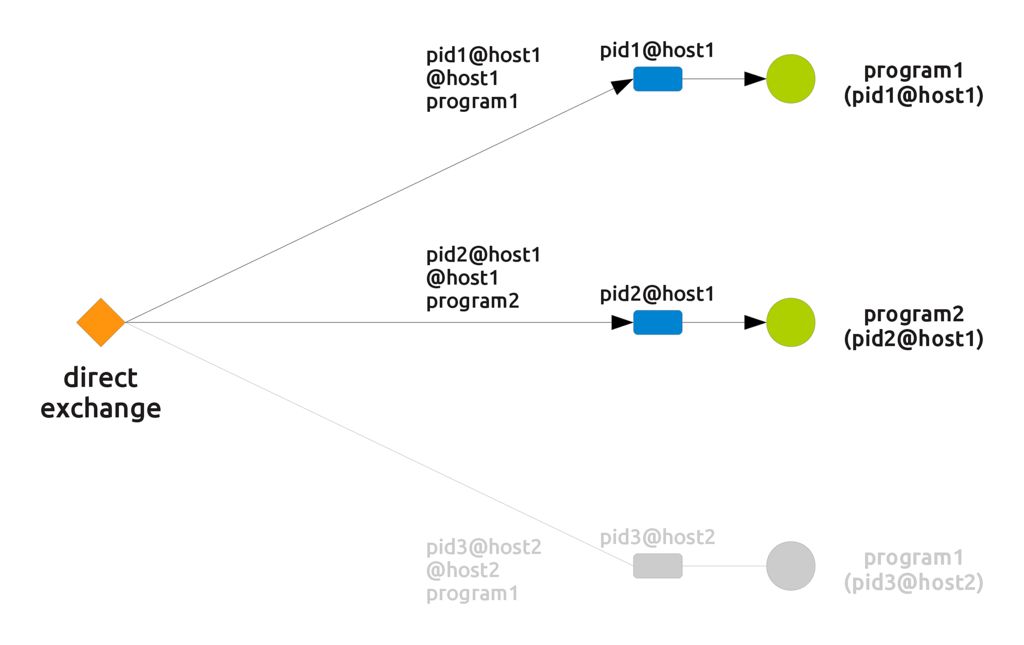
If the routing key changes to "program1" the connections become the following
Direct exchanges and load balance
In the previous section we looked at a smart use of the third of the three configurations explained at the beginning of the post. We can profitably leverage the second one (the "round robin" case) to selectively reach cluster programs while balancing the load. Remember that the main use of a round robin message delivery is indeed to avoid overloading a single component or machine.
To balance the load among a set of programs we need each of them to declare a queue and share it with others: in other words we need to declare a queue with a shared name. This is very easy: for each of the properties of our programs a shared queue can be declared simply by naming it with the value of the property itself.
For example, declaring a queue named "@host1" creates a queue shared by each program running on host1, while a queue named "program1" is shared among all the programs running the same executable. Even PIDs can be used in this way, but since it is usually not interesting to get the set of all programs on the cluster running with the same pid, there is also no point in defining queues based on them.
In defining such queues you need to define a syntax (just like for the previous "fanout" case) to avoid name clashes; this is the reason why host routing keys have been prepended the @ sign. Otherwise, a process named as one of the hosts would break the routing scheme.
The resulting setup is portrayed in the following picture
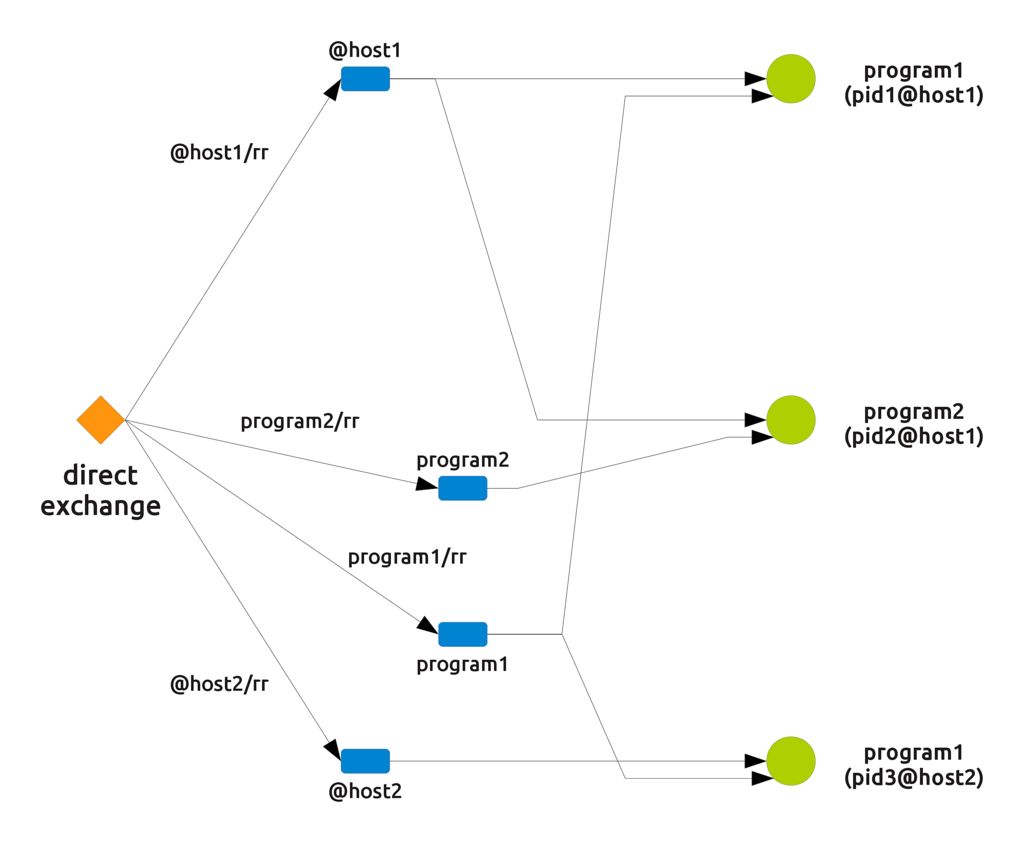
Here you can see, for example, that sending a message with the routing key "@host1/rr" makes the message flow into the queue called "@host1", which is shared by all the processes running on that host. Since the queue is shared, messages are not duplicated but delivered in a balanced way. The "/rr" suffix stands for Round Robin and usefully tells apart fanout routing keys from load balance ones.
Conclusions
Well, after all I just explained again and more verbosely the basic RabbitMQ examples, didn't I?
Yes. However, I think such considerations can be useful for novices and from time to time it is a good thing for experts to refresh the plain old basic stuff. So this post can be used as a quick memo of the different configurations you can create with an AMQP direct exchange.